HIVE developmet with limited computing resources: Tips needed.
5 comments
After a stormy time in my private life (my long and nasty divorce, my move to my own place, financial struggles due to legal bills and credit registrations tied to my ex, major relationship problems in my relationsip with the great love of my life, and mental health problem and a full on panic attack that had me think I was dying), I'm starting to seek for more structure in my life right now, and with the moment of my divorce finaly becomming final, finaly comming in sight, picking up development efforts again soon seems like an important step towards picking up my life again and with some structure.
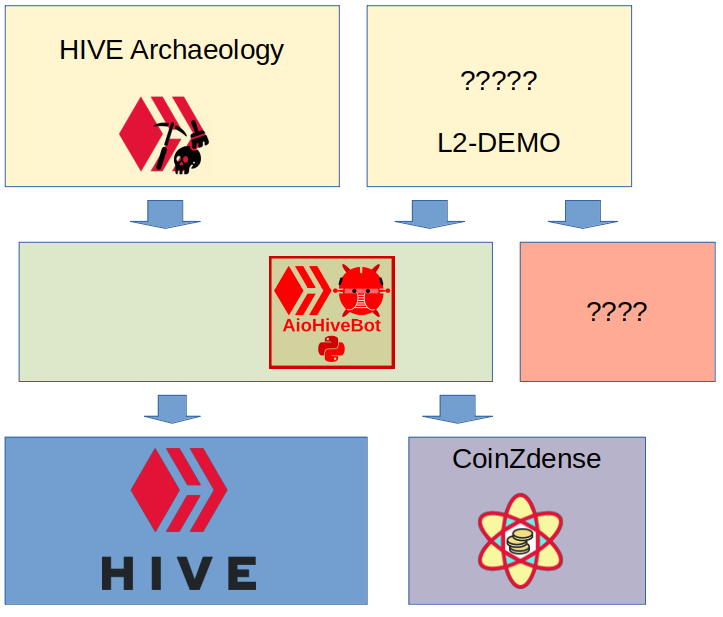
My goal for development right now is a practical proof of concept that links three of my projects:
Hive Archeology Bot
The HIVE Archeology bot is a simple private bot that currently a user can run for example on a nas using docker, and that monitors that user's upvotes. If the bot detects that it's owner upvotes a post that is past the upvote window, the bot uses a simple sceme to still reward the post's creator. It:
- Creates a comment and sets the benefactor of the comment's reward (mostly) to the creator of the post that the user tried to upvote.
- It waits for a little while and then upvotes the comment.
This way, while the reward window for the post has expired, the post creator still get's rewarded. It's a little bit more advanced than that because I was anticipating more users of my bot, so the bot also looks for similar active comments from other users that it might hitch a ride on instead, but this is the gist of it.
The Hive Archeology Bot currently runs on top of lighthive by @emrebeyler, a really good Python HIVE library, IMHO much more production suitable than the often linked to beem, that is quite suitable for the task of a small personal bot, but as it's the only bot that I currently have as candidate for my proof of concept that included the aiohivebot library, I aim to port the Hive Archeology Bot to aiohivebot.
AioHiveBot
The aiohivebot library is a python library for HIVE that doesn't try to be general purpose. It is a library specificly meant for writing HIVE bots that leverage the Python asynchonous model of operation. Target applications would likely integrate with async web frameworks like aiohttp or starlet, allowing to build bots with their own web front-end or REST or JSON-RPC API.
The library is build to not rely on a single HIVE API node, it connects to all known API node and periodically probes their operations, balancing API calls to the non-broken nodes as good as it can. This should make for more robust HIVE bots that don't fail if by chance the one node they connected to starts failing. Fall over is fully abstracted by the python API.
Next to this, the aiohivebot is always streaming new blocks. If your bot doesn't need this, then aiohivebot is not the library for you. It's not general purpose.
Apart from layer-1 HIVE access, aiohivebot also allows streaming layer 2 events, though currently only from hive-engine
Currently AioHivebot doesn't support signed operations yet. Signed operations need to be streamlined with the aiohivebot design, and the actual signing is partially going to end up in the coinzdense library. I haven't fully designed the hand-over between the two yet, but the goal is to move as much as possible to coinzdense but only those parts that can reasonably be parameterized so they would be usefull for other chains too. Basicly aiohivebot should contain the parameters and the HIVE specific code, including code needed for pigybacking hash-based post-quantum signatures and key meta-data onto HIVE operations, while CoinZdense contains the parameterizable bits doing the actual signing.
CoinZdense
HIVE uses ECDSA for signing, and key-reuse is part of its core design. In a number of years quantum computers are expected to make it possible to reconstruct an ECDSA private key from an ECDSA public key, and public keys on HIVE are really public. This means that HIVE, and multiple other ECDSA based Web 3.0 chains will some day be extremely vulnerable to Quantum Computer based attacks. We are still quite some years removed from this reality, but it is undeniable that it is a reality that is comming, so it is better to start preparing.
Hash-based signatures can be an awnser to this threath, and the goal of CoinZdense is to provide such hash-based signatures, but not just that; provide them in a way that opens up least-authority key management to the Web 3.0 space.
HIVE has OWNER, ACTIVE and POSTING keys, providing some level of reduced authority, but what if I want to write a bot that only needs the authority to post comments and upvote? What if I want a bot that is only able to post custom JSON operations for one specific L2? Maybe even only such operations that represent specific operations within that L2?
CoinZdense aims to accomodate this, not just for HIVE but for Web 3.0 in general
Piggyback proof of concept ?
My goal is to work on these three projects, make AioHiveBot use CoinZdense for signing, cooperate with it to piggyback a proof of concept hash-based-signing setup on regular ECDSA signed HIVE operations. Make the HIVE archeology bot use aiohivebot insteade of lighthive so running the HIVE Archeology Bot will function of a proof of concept and decent test run for hash based signatures.
Once the proof of concept shows me that things work, a forrlowing step should probably be scaling up. I have some incomplete ideas for a proof of concept L2, likely involving FlureeDB and aioflureedb (see @aiofureedb's posts) and least authority file sharing based on pyrumpeltree but these ideas need a lot more work.
Impact and needing my own HIVE node?
A big part of the proof of concept will be minimizing and evaluating the impact of pigybacking hash based signatures and key meta-data onto the L1 chain, and while I'll have some insights using public API nodes, it would seem like a good idea to start using my own HIVE node, so I can see in detail what impact my pigyback efforts have. Next to this, my own node could allow me to gain enough knowledge to write a proposal for new HIVE-core features that could move esential parts of the piggyback implementaion into the HIVE-core, adding features and the first seeds of an integration and migration paths.
Running a node takes resourced that I'm currently low on. I have a single i5 based Minisforum MS-01 with 96 GB of RAM, a 4TB gen-4-PCIe M.2 SSD and a 2TB gen-3-PCIe M.2 SSD. Not too shabby, but apart from a 8GB Orin Nano, it's my entire hom,e development infrastructure. The specs tell me I need to fully dedicate my 4TB SSD to the HIVE node and it might already be tight because I don't know how old these specs are.
CICD
In my day-job I use Gitlab, docker and CICD to streamline my development efforts, a full gitlab configuration with docker runners for CICD eats up quite a bit of resources, resources I might not have left if I run my own HIVE node.
FlureeDB
I won't really need it for my proof of concept, but when I move on to trying to create a simple proof of concept L2 for least authority file-sharing, I'll need to run FlureeDB on my setup.
Xen and a OpenBSD firewall and internet facing web layer.
On the one hand I'm thinking that having limited resources and it being just a proof of concept right now, I should just run one Ubuntu instance on the base metal of my Minisforum MS-01. But on the other hand, if it ever grows beyond the proof of concept, a more professional setup with Xen running on the system, multiple DOM-Ns running in seperate virtual networks, an OpenBSD based firewall being one of them, and a second OpenBSD system with NginX being the only directly internet facing Dom-N gives me a much more solid start, even if it will eat up recious resources from my (almost, the Orin Nano hardly counts except for CUDA CoinZdense experiments that might end up core library) single system.
Insights please

So to anyone running their own HIVE node, especialy those doing development with it, what are your insights? What yould you do and prioritize to start developing in a structural way for a HIVE Proof Of Concept like the one I'm proposing, a POC personal bot (plus stack) that at one time should make room for for a POC L2 node for least authority file-sharing. And a POC that hopefully will give me enough info to write proposals for HIVE-core in the future.
I'm trying to get my shit together and pick up development again, but configuring my 96GB 4TB+2TB i5 based MinisForum MS-01 to do so has me wondering what path to follow to get a setup suitable for structurally working on these three (eventually four) projects and their interoperation.
So guysm HIVE-devs, please help me out with some sane advice? Should I go Ubuntu on raw iron to maximize resource availability so I can cram more onto my system? Or should I use Xen/OpenBsd to do things more future proof and professional? Should I start out with running my own HIVE node and structure the rest around that? Or should I delay running my own node and focus on getting my CICD shit together with Gitlab and docker runners, maybe throw in FlureeDB already in my setup so the step from POC bot to POC L2 node becomes less of a hurdle in the future?
Any insights and tips will be highly apreciated, so please weigh in, and help me get my shit together on this. While mentally I'm still close to the bottom, I'm slowly crawling out, and I feel structure in my life and time spent on building things again is going to help me get things more on track again. I don't know if my great love and I have a future, but I know she needs me to stop focusing all my time and atention on her now that my divorce will soon stop being a never ending source of financial and emotional turmoil, and my new home is starting to be livable enough to stop working on it. She needs her space and I need te refind structure, and having a system I can do it on, I think, is going to help me refind structure while giving her the space she needs.
So any advice that helps me figure out how to setup my dev machine will do more for me than just help me set up my dev machine.
Comments